목차
"빅데이터의 시작! Raw Data를 수집하자."
대량의 데이터(File, DB, API etc..)를 수집 도구(Nifi)를 통해 수집한다. 이때 비정형 데이터를 일관성 있게 수집하는 것이 중요하다.
그리고 API의 경우엔 간혹 실시간으로 유입되는 데이터를 수집해야하는 경우도 있는데 이런 경우는 자동으 수집되게 배치 스케쥴러를 구축해야한다.
"수집된 Raw Data를 정제하고 저장하자."
수집된 원천 데이터는 하둡에 바로 저장하는 것이 아니다. 정제 후 저장해야한다. 비정형 데이터를 구조적 형태(시계열, 코드 기준)로 변환이 필요하다. 또 데이터 노이즈(무의미하거나 잘못된 정보)를 제거해야한다.
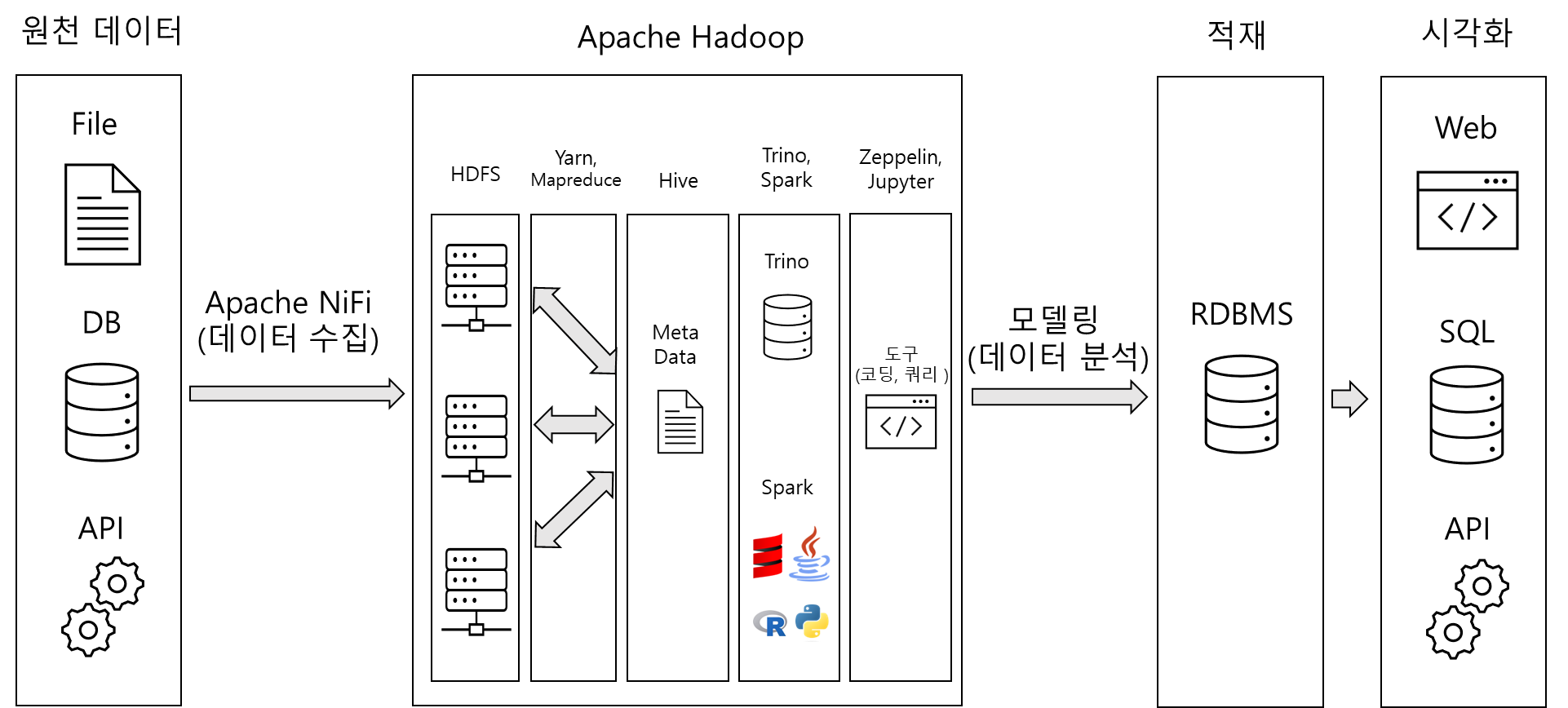
빅데이터의 핵심은 저장하는 것이다. 이유는 이때 대용량 데이터를 관리할 수 있는 Hadoop이라는 시스템을 사용하기 때문이다. 그리고 Hadoop에는 빅데이터를 관리하기 위한 여러가지 Ecosystem인 HDFS, Yarn, Mapreduce, Hive, Trino, Spark 등이 있다. 다음 이미지를 보면서 설명하겠다.
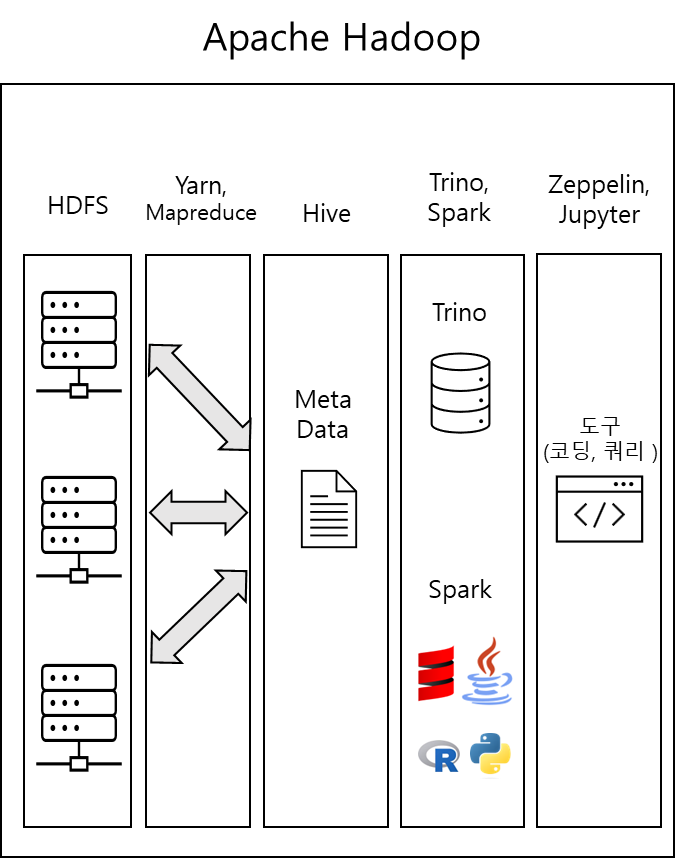
HDFS는 대용량 데이터를 분산하여 저장할 수 있는 Hadoop Distributed File System의 약자이다. 대용량 데이터를 저장했다면 대용량 데이터를 분석하기 위해 데이터를 조회할 수 있어야 한다.
이때 주로 사용하는 것이 웹 기반 Notebook이며 시각화 도구이다. 시각화 도구로 주로 Zeppelin과 Jupyter를 사용한다.
데이터를 조회하는 처리 과정은 다음과 같다.
① Zeppelin이나 Jupyter에서 코드 또는 쿼리를 입력한다.
② Trino또는 Spark에서 해당 문법을 컴파일한다.
③ Hive에는 Meta Data를 가지고 있기 때문에 Hive를 거쳐야한다.
④ 이후 Mapreduce또는 Yarn을 통해 분산되어 있는 서버(HDFS)에서 데이터를 가져온다.
⑤ Zepplin또는 Jupyter에서 응답받은 데이터를 출력한다.
Hadoop Ecosystem은 다양하다. 이것을 상세하게 알고 있는 것이 중요하다. 먼저 Mapreduce와 Yarn의 탄생 배경에 대해 알아보자!
"Mapreduce 그리고 Yarn의 탄생 배경"
Hadoop 1.0에서는 Mapreduce만 사용했었다. 당시에는 대량의 데이터를 처리하기 위한 최고의 기술이었지만 메모리를 사용하지 않은 Disk기반이었기 때문에 매우 느렸고 코드도 일반적이지 않았다. 이 때문에 성능 향상을 위해 메모리기반인 Spark가 나타났고, 관리를 위해 맵리듀스로 변환해줄 수 있는 언어인 Hive가 나타났다. 그럼에도 해결되지 않은 여러 문제들을 가지고 있었고 이를 해결하기 위한 기술인 Yarn이 등장하였다.
"Mapreduce 대표적인 문제가 뭘까?"
여러가지 문제가 있지만 대표적으로 Mapreduce는 HDFS에서 데이터를 가져올 때 서버가 죽으면 실패가 뜨고 데이터를 가지고 올 수 없었다. 하지만 Yarn은 죽은 서버를 실행시켜 살리고 가져올 수 있게 되어 안정성이 높아졌다. 이 밖에도 많은 문제점을 Yarn은 개선하였다.
"Spark와 Trino는 뭐가 다를까?"
Spark :
① Scala, Java, Python, R 등 언어를 지원한다.
②여러 노드에 분산하여 RDDS(Resilient Distributed Datasets)라는 분산 데이터 객체를 사용하여 데이터를 처리하기 때문에 장애 회복 기능이 있다.
③ 머신러닝 라이브러리와 그래프 처리 라이브러리를 지원한다.
Trino :
① SQL문법을 사용 가능
② MySQL, PG등 많은 DB 저장소를 지원한다.
④ 쿼리 자동 최적화로 빠르다.
Ecosystem별로 특징이 다르다. 또 최신 기술일 수록 성능이 향상되고 있기 때문에 신기술을 학습하는 것은 매우 중요하다.
"저장된 데이터를 다양한 형태로 가공하자!"
정제되어 저장된 데이터는 집계 함수 등 분석에 알맞은 형태로 가공한다.
"분석 도구를 활용하여 데이터를 분석한다."
데이터 분석은 Zeppelin이나 Zookeeper 등 분석 도구를 활용해 도구별 지원하는 언어로 데이터를 확인하며 분석할 수 있다.
"시각화를 위해 목적에 맞는 DB에 적재한다."
필자는 RDB인 PostgreSQL에 적재하는 경우가 많았다.
"마무리! 니즈(Needs)에 따라 시각화를 한다."
데이터를 외부에 공개하기 위해 웹 애플리케이션에서 차트나 API서버를 구축을 하는 경우가 일반적이다. 그러나 반대로 사내에서만 사용하고 SQL지식이 있는 경우는 구축할 필요 없이 DB툴로 조회를 하여 확인한다.